 Figure
4-1: SuperDAAC Hardware Platforms
Figure
4-1: SuperDAAC Hardware PlatformsThis section proposes a feasible hardware design for the 2 superDAACs and the N peerDAACs. We first explore the design requirements that a superDAAC must meet. These requirements include storing the raw data feed from the EDOS, constructing a collection of standard products (eager evaluation), executing a set of ad hoc queries (lazy evaluation), and supporting batch processing by reading the entire store sequentially in a reasonable period of time. These design requirements are discussed in detail in Section 4.1.
In Section 4.2, we indicate a generic architecture composed of 4 componentsó tape silos, disk caches, computation engines, and DBMS enginesówhich we believe can satisfy the design requirements. This generic architecture is then specialized to real-world COTS hardware components to produce 6 candidate systems that can be built in 1994. Because covering the details of the component selection, ensuring that there are no bottlenecks, and satisfying the design requirements are all complicated tasks, we place these discussions in Appendix 6 for the interested specialist. In Section 4.3, we present 1994 cost estimates for 2 of these systems, one based primarily on supercomputer technology and one based on a network of workstations. A system can be produced costing between $259M - $407M in 1994 dollars for 2 superDAACs. (In Section 5, we use these numbers, discounted by expected technology advances over time, to determine the hardware cost of a phased, just-in-time deployment schedule that will meet EOSDIS objectives.)
Section 4.4 turns to the 1994 cost of peerDAAC hardware. Again, these numbers will drive a just-in-time deployment schedule in Section 5.
In this section, we indicate our major assumptions to drive our superDAAC hardware sizing:
Table 4-1 summarizes this set of design criteria, using the current launch schedule and definition of level 1 and 2 standard products.
| Tape archive | Size of raw feed plus level 1 and 2 products for 3 years, plus some spare capacity | ||
| Design requirement | |||
| Design requirement | |||
| Design requirement | |||
| 4 bytes per 64K of data is .0006% | |||
| Disk cache | Design requirement | ||
| Design requirement | |||
| Computationóeager | Each superDAAC does 50% of eager evaluation | ||
| Raw feed | From HAIS design documents | ||
| From HAIS design documents | |||
| Level 1-2 products | From HAIS design documents, with 50% eager evaluation | ||
| From HAIS design documents | |||
| Each superDAAC does 50% of the computation listed in the HAIS design document | |||
| Computationólazy | Design requirement | ||
| Design requirement | |||
| Design requirement | |||
| Design requirement | |||
| The superDAAC does 1/3 of the computation; the peerDAAC does the other 2/3 | |||
| Computationóreprocessing | Design requirement | ||
| Design requirement | |||
| Design requirement | |||
| Design requirement |
The resulting design for the superDAAC is:
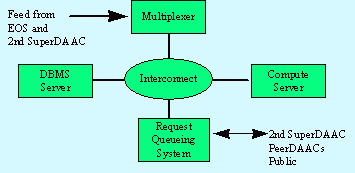
The basic hardware components of the superDAACs are illustrated in Figure 41. They consist of a data multiplexing platform to support the raw feed, a database platform, a request queueing platform, and compute platforms. A high-speed network links the platforms.
The superDAACs support 4 data flows:
Figure
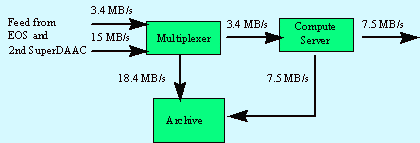
4-1: SuperDAAC Hardware PlatformsFigure 4-2 shows the associated data flows for eager processing of the raw feed. The input data stream contains both the raw feed and the data that is being backed up from the other superDAAC. The compute platforms process only the raw feed data and store half of the results in the data archive. These data are backed up to the other superDAAC.
 Figure
4-2: Eager Processing Data Flow
Figure
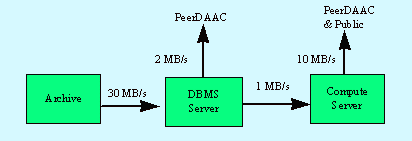
4-2: Eager Processing Data FlowFigure 4-3 shows the associated data flows for processing interactive queries to the database. Data is pulled from the archive in 100-MB chunks. The appropriate data subset is generated. The processing is then split between the superDAAC and the peerDAACs, with 1/3 of the processing being done at the superDAAC.
 Figure
4-3: Lazy Processing Data Flow
Figure
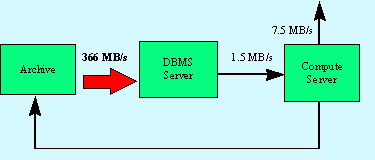
4-3: Lazy Processing Data FlowFigure 4-4 shows the associated data flows for the data streaming system that supports queued requests. Half of the data archive is streamed through the data-subsetting platform at each superDAAC. A data subset is generated that is equal in size to 2% of the accumulated raw feed. This, in turn, is processed to create new products. Half of the resulting data is stored back in the archive.
 Figure
4-4: Streaming Data Flow
Figure
4-4: Streaming Data FlowA detailed design of superDAAC hardware that specialized this architecture to 6 collections of 1994 COTS hardware components is discussed in Appendix 6.
In this section, we present 2 example configurations that are discussed in detail in Appendix 6 and meet the design requirements of Section 4.1. Table 4-2 describes the superDAAC configurations.
Table 4-2: SuperDAAC Configurations
Both use an IBM tape silo, an NTP 3495, and a CRAY Superserver made up of SPARC processors (CS-6400) as the request queuing system. In the workstation-oriented system (WS), a DEC Alpha machine (DEC 7000) forms the basis for the compute server and the database platform. A large collection of interconnected machines is required to satisfy the load, and an ATM switch is used to provide connectivity.
The second configuration is more conservative and uses a CRAY C90 as a compute server (instead of a network of workstations) and a CRAY CS-6400 as a DBMS engine. Table 4-3 indicates the 1994 hardware cost of each configuration.
The table indicates the number of each component needed, the aggregate cost of each component, and the total hardware cost.
Notice that the conservative design is $203M, while the network of workstations saves dramatically on the compute server and costs $129.5M.
In our opinion, these 2 designs bracket the reasonable costs of a real system and can be used safely for the cost analysis in Section 5.
A modified version of the design criteria used for the superDAACs can be applied to the design of peerDAACs. The same hardware systems are used: data storage devices, database server platforms, network switches, and compute servers.
However, we assume 2 different load requirements for peerDAACs:
In Table 4-4, we indicate the sizing of 2 minimal peerDAAC configurations, one based on the IBM RS/6000 and the DEC TL820 tape silo, and the second based on a DEC Alpha and DEC DLT tape stacker. Note the total price of a minimal peerDAAC varies between $2.04M and $3.52M.
| ||||||||||
In Table 4-5, we scale the 2 options upward to satisfy the requirements of a large peerDAAC. The cost climbs to $2.86M to $4.22M.
These numbers will be used in Section 5 for downstream peerDAAC cost estimates. The details of peerDAAC configuration appear in Appendix 6.