Big Sur: Base Schema
- Section Coordinator:
- Jean Anderson, jean_anderson@postgres.berkeley.edu
- Last Updated:
- $Date: 1995/05/23 20:01:05 $

Introduction
The first layer of the Big Sur database infrastructure,
the base schema,
establishes a framework to support the database management and
processing needs of Sequoia applications.
Our goal is to establish reusable building blocks composed of
types
and
tables that are useful to many
applications.
This is like a code library that supplies functionality shared by
many applications.
The library includes functions all applications need;
however, it probably does not include every function a single
application needs.
Likewise, the Big Sur base schema might not include all building blocks
an application needs.
We will work with and encourage researchers to extend the base building
blocks as needed for a specific application purpose.
We will watch for application-specific building blocks that satisfy a
more general need and will incorporate them into the base schema.
This section describes the base building blocks in detail,
organized as follows:
-
- We explain why a typical schema design approach does not scale for
Sequoia and describe an alternative based on emerging
geospatial data standards:
-
- We describe the basic SQL building blocks implemented in the
Illustra object-relational database that support earth science
data:
Researchers use these building blocks to create a database for
a particular application.
Design Approach
Big Sur schema development is drawing from geospatial standards to:
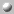 Accelerate schema development.
Accelerate schema development.
- Many person-years have already been invested defining data components
that Sequoia can use today.
-
Avoid tuning the schema to any single application.
- Integrating new applications should not require changes to the base
schema; rather, the base schema should be extended to support new
applications.
-
Support interoperability.
- Most of the geospatial standards have been designed with interoperability
in mind; many of them already provide tools.
First we describe a typical
schema design approach and why it does not scale for Sequoia data.
Next we describe a standards-based approach,
focusing on the
Spatial Archive and Interchange Format (SAIF)
[SAIF94]
and the
Content Standards for Digital Geospatial Metadata (FGDC)
[FGDC94] standards.
Finally we mention a few lessons learned
so far and where we expect our approach to fall short.
Typical Design Approach
Schema design requires defining a framework that, at minimum, specifies:
- High-level objects, such as a satellite image,
global circulation model, or map projection.
- Relationships between objects; for example, a satellite image
is registered in a specific map projection.
- Low-level attributes, such as a temperature or latitude,
along with their types.
- Domains of valid values and data integrity constraints.
- Standard terminology and naming convention.
- External interfaces.
The goal is to produce an application-independent schema. For example,
software that displays a satellite image should not require a different
underlying schema than software that transforms objects to a different
map projection.
However, establishing a base framework is labor-intensive, even for a single
data domain or application.
First of all, the schema designers must thoroughly understand the data domain
and processing requirements.
References such as [FLEM89]
are used by many database organizations and
establish a schema design strategy that encourages a sensible, data-driven
approach independent of any specific application.
However, since it is easier to understand a known application than
the underlying data domain, the design process often results in
application-specific schemas that must be altered to add new applications.
A large body of literature describes schema evolution, transformation,
and migration strategies; see, for example,
[ROSE94] and
[HURS94].
Secondly, even with a well-understood data domain,
specifying objects takes much longer than anyone would imagine.
Given a longitude, does the database attribute get named
longitude, Longitude, lon, or long?
Is the type a single or double precision real?
or perhaps in decimal degrees, minutes, and seconds?
Does the valid domain go from -180 to +180? or from 0 to 360?
[BRIG94] cites a study that shows that the likelihood two people will choose
the same name for an object ranges from 7% to 18%.
Viewed another way, disagreement is the expected norm and
concensus is time-consuming to achieve.
This approach does not scale for Sequoia. Sequoia has scarse labor resources,
a high number of applications, and--most importantly--many data domains to
integrate.
The Catch 22 is
the researchers who understand each data domain do not understand schema design and
the schema designers do not understand the science domains.
A different schema design approach is needed, one that does not require
scientists to become schema designers and that does not require schema
designers to become fully versant in each science domain.
Standards-Based Approach
Sequoia data are as diverse, if not more so, than most standards efforts.
Furthermore, base standards for the Sequoia domains have already been at
least partially established many times. Together
[JOHN92] and
[CASS93] identify over 50 standards related to GIS
mapping and remote sensing technologies alone.
The time such efforts take is staggering:
- DIGEST, the international digital geographic standard, took 30 person-years
[CASS93].
- SDTS, the U.S. Spatial Data Transfer Standard, took 10 chronological
years [CASS93].
- SAIF, the Canadian Spatial Archive and Interchange Format specification,
has taken an estimated 10 person-years so far
[SAIF94].
Sequoia does not have person-years of resources available to develop a
standard that encompasses all Sequoia data domains.
We must leverage
the person-years others have already been spent defining many data elements
we can use now; and we should work with the standards organizations to
extend the standards as needed.
At the very least, checkpointing schema development against the relevant
standards will help ensure that the base schema remains domain- and
application-independent.
Current Sequoia schema development is based on a hybrid of the
FGDC metadata and SAIF
standards.
Our goal is to use FGDC at the high-level, especially for data set
information, and fill in from SAIF for more complex constructs.
Where the two standards overlap, we will provide views that present
data from either perspective.
Both standards are briefly introduced next.
Spatial Archive and Interchange Format (SAIF)
SAIF was accepted as a draft standard by the Canadian General Standards
Board in 1991[SAIF94].
It is an extensible, object-oriented data modeling and archival/transfer
standard that targets both geospatial and non-geospatial data.
[ANDE94] describes a raster
prototype based on SAIF and implemented in the Illustra object-relational
database.
The advantages of SAIF include:
- It is highly extensible.
- The designers are committed to integration with other standards.
- It is available electronically and is freely redistributable.
- Source code for the toolkit api is freely available.
The disadvantages of SAIF include:
- It is very large, defining over 300 constructs.
- Its object-oriented approach is complex, making it a significant
spin-up.
- Its style is very different from the FGDC metadata standard.
Content Standards for Digital Geospatial Metadata (FGDC)
The Federal Geographic Data Committee (FGDC) started specifying a digital
geospatial metadata standard in 1992, resulting in a final draft
published in 1994 [FGDC94].
It adopts a simpler data model organized into the
hierarchy of data and compound elements needed to
document a geospatial data set.
The FGDC metadata standard is particularly useful for high-level metadata
and appears to be gaining popularity in the
geospatial user community.
The advantages of the FGDC metadata standard include:
- It is a simpler data model.
- It is small.
- It is available electronically and is freely redistributable.
- It already has growing popularity in the geospatial user community.
The disadvantages of FGDC include:
- It is incomplete.
- It does not have a mechanism for describing extensions.
- Its style is very different from SAIF.
Lessons Learned
The lessons we have learned so far include:
- Standards do accelerate development.
- Standards are too big and too little:
- profiles (subsets) need to be supported
- extensions need to be supported
- information about profiles and extensions must be transferred
Some standards readily support user profiles and extensions,
such as SAIF. Others do not, such as FGDC, although it is
a continuing topic in the FGDC metadata working groups.
- Each standard is biased towards a particular domain; for example,
FGDC and SAIF are GIS-centric.
Big Sur must support views that support other science domains.
- There is a significant spin-up on standards, even on the FGDC
metadata standard, especially for scientists unfamiliar with the
GIS domain.
- It is possible to impact the direction of a standards effort.
SAIF Version 3.2 includes changes to the Raster type, which the
designers made in direct response to Sequoia feedback.
- Standards do not necessarily interoperate.
We have also noticed a few weaknesses in our approach:
- Creating a hybrid schema out of SAIF and FGDC produces an
inconsistent style. For example, FGDC and SAIF naming conventions
are obviously different. We think we should live with this
inconsistency for now rather than try to reconcile the two styles.
- The way we implement these standards may not produce optimal
database performance; the actual implementation will need to be
tuned over time.
Base Schema
The Big Sur base schema is made up of base types and SQL template
create statements, which researchers use for creating
a database schema for a given application.
We will work with researchers to extend the building blocks
as they need to meet application requirements.
This section describes:
Design Guidelines and Software Requirements
First we mention the software requirements since they drive some of
the guidelines. The Big Sur base schema requires:
- Illustra object-relational database
- Illustra 2D spatial blade
- C compiler
We recommend that researchers follow these guidelines as they extend the
Big Sur base schema:
- Building blocks should only depend on SQL or C.
Additional functionality using another language may be
introduced at the higher Middleware or
Application levels.
- Building blocks should be based on either the
FGDC metadata or SAIF
standards wherever possible.
- Although Illustra supports composite types, we have not implemented
them in this release. User response to them has been variable;
experienced users seem to think composite types simplify the design,
less experienced users find them to be a steeper learning curve
(for example, updates and inserts require referencing all attributes,
and indexing must be done via a function).
We think a "flatter" schema is an easier starting point, but
we may take advantage of composite types in a future release.
- FGDC implementation notes:
- We use FGDC names as is, unless noted (see the note on
Illustra types below for an example).
- For the most part, required attributes have a NOT NULL constraint
in the SQL create statement, optional attributes do not.
Some constraints have been relaxed initially to encourage
researchers to load incomplete metadata.
- We use Illustra types wherever they are
advantageous. For example, Spatial_Domain in
Identification_Information is an Illustra Poly
to take advantage of spatial searches. This deviates from
the specification, which requires Bounding_Coordinates
and optionally a Data_Set_G-Polygon. Illustra supports
storing a Box as a Poly and casting back to Box. Furthermore,
we can easily extract the
{East,West,North,South}_Bounding_Coordinate elements
in Bounding_Coordinates.
- We replaced some description fields,
such as Security_Handling_Description (Section 1.12.3),
with a generic Description table.
We encourage researchers to
inherit
Description wherever they want to track additional
descriptive information.
- We simplify some of the FGDC hierarchical and recursive
relationships. For example, we left out the recursive
citation.
- SAIF implementation notes:
- We use SAIF names and definitions as is, documenting
any deviations from the SAIF standard.
- Big Sur Version 1 implements enumerations as text strings.
We have implemented enumerations separately as new base types
and may incorporate them into the base schema in a later release
of Big Sur.
Our main issue is the domain of valid values for some of them,
such as UnitMeaning, needs to be dynamic.
Our tentative plans are to make dynamic enumerations table
driven. The rest would be implemented in C code for efficiency.
The underlying implementation would be transparent to the end
user.
- Big Sur Version 1 splits SAIF lists out ("normalizes") into
separate tables rather than implement them as Illustra arrays.
While this produces a more relationally "pure" schema,
we have noticed that it has been more difficult for end users
to grasp, something we will consider during Version 2 design.
- Conventions for extensions that do not fit either FGDC or SAIF:
- Table names:
- begin with uppercase letter,
- are singular,
- have a type defined that is the {name}_t.
- Attribute names that are not an oid ref():
- start with lowercase
- should indicate the data domain to which it belongs.
- Attribute names that are an oid ref():
- name of the table it points to.
For example,
Lineage.Identification_Information is a
ref(Identification_Information_t) to access
data in the Identification_Information table.
- Documentation:
Complete descriptions for new attributes must be provided,
including any rules or data integrity constraints.
SQL Tables
Big Sur tables may be used directly, or they may be
inherited to support a user-defined
schema.
The Applications section
shows how these building blocks are applied and extended by the
Sequoia
remote sensing
and climate model applications.
We have grouped the tables into the following categories:
- Big Sur Version 1 (implemented)
- Data Set Metadata
- Lineage
- Grid
- BigSur Object
- Big Sur Version 2 (in progress)
- Projection handling
- Accuracy, uncertainty, and error
- Vector data
Also populate shared reference data sets, such as coastal outlines
and ecosystem boundaries.
- TOPEX/Poseidon Point data
- Field Measurements Data
Each implemented category is described in this section and contains the
following minimum information:
 Entity Relationship Diagram (ERD)
Entity Relationship Diagram (ERD)
- Entity relationship diagrams are useful for creating visual
road maps of a database schema.
Clicking on this one will bring up a description of the notation.
- SQL Code
- Clicking on any SQL Code reference will bring up source code.
- Reference
- Clicking on the reference will take you to the document
containing detailed information about the attributes, if such
a document exists.
1. Data Set Metadata
Data set metadata describe the data sets
that are available at a particular site as well as detailed information about
each data set. The Big Sur implementation is based on the
FGDC metadata standard.
Big Sur Version 1 implements
Identification Information
and
Metadata Reference Information,
the two required compound data types.
Detailed information for this part of the schema includes:
-
ERD: Data Set Metadata
-
SQL Code
-
FGDC Metadata Standard
2. Lineage
Lineage describes the processing history, algorithms, and parameters that
were used to process the data.
Detailed information for this part of the schema includes:
-
ERD: Lineage
-
SQL Code
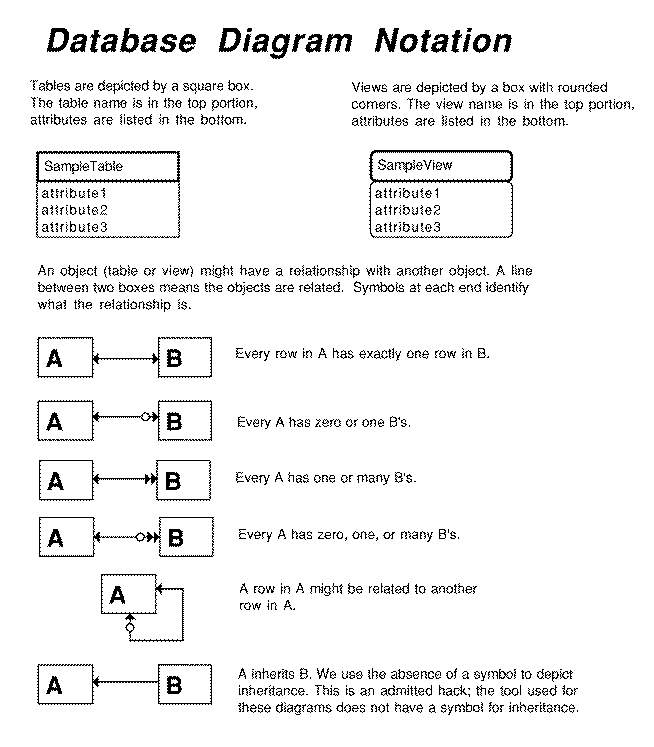
3. Grid
Gridded data in the Big Sur schema
is multi-dimensional and georeferenced.
An initial cut of a grid is nailed down for remote sensing and climate
modeling data. Georeferencing is partially nailed down, but we need to
include projection handling.
Detailed information for this part of the schema includes:
-
ERD: Grid
-
SQL Code
-
SAIF Standard
Additional explanation follows.
SAIF 3.2 changes the SAIF 3.1 specification
in the following ways:
- StructuredData
Eliminated.
- ElementStructure
Eliminated.
- Channel
New class manages raster band information. We think it is also
useful to manage climate model variables and is the basis for
the CellVector tables we have implemented.
We are additionally modifying the SAIF specification as follows:
- CellGeometry
Not implemented. If anyone needs it, let us know.
- positionOfOrigin
In the SAIF standard, it is a Point.
This relational implementation normalizes it into one row per
axis per the diagram below.
- originCoordinates
SAIF specifies that it is a list of ones or zeroes unless it is
located with respect to a larger grid. Some applications need
to specify originCorner at a specific cell, not the
relative topRight, lowerLeft etc. values in the
OriginReference enumeration. We think
GridReference.originCoordinates could be used for this.
Like positionOfOrigin above, this relational
implementation normalizes it into one row per axis per the
diagram below.
- Channel
Channel is specific to remote sensing data; however, we have
found it useful for model data as well. We renamed it
CellVector.
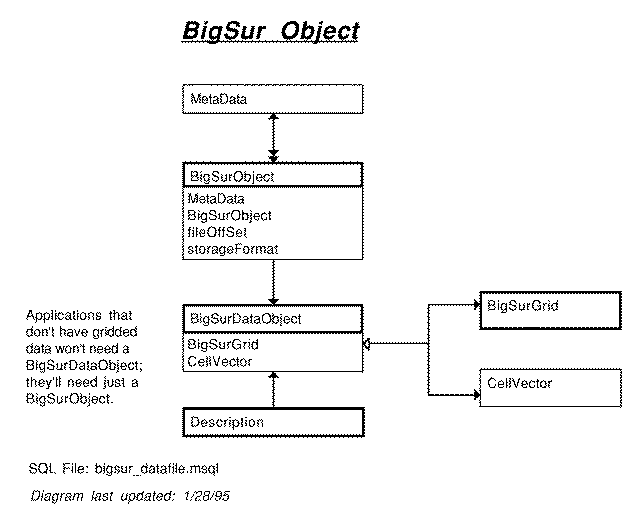
4. Big Sur Object
BigSurObject contains the data
granule.
Detailed information for this part of the schema includes:
-
ERD: BigSur Object
-
SQL Code
Base Types
This section describes the type building blocks in the Big Sur schema.
So far, these new base types are implemented or planned:
- Big Sur Version 1 (implemented)
- dlobh (distributed large object handle)
handles large_object and external_file types.
- mdarray, multi-dimensional array type,
is implemented but not distributed and in use yet.
- SAIF Enumerations are available but
not integrated into Big Sur yet.
- Big Sur Version 2 (planned)
- Extend dlobh to handle image, text, and
GRASS types.
- Move mdarray into production use.
- Integrate SAIF Enumerations.
- Integrate the general cartographic transformation package (gctp),
produced by the USGS, which transforms between 30 projections.
A brief introduction to each type is below; complete information is
forthcoming.
1. DLOBH
The Distributed Large Object Handle (dlobh) provides location-transparent
access to Illustra large_object and external_file objects.
Key features include the ability to mix Illustra large object types in the
same attribute in a table and to access objects on a remote Illustra server.
The following functions provide input/output support for msql
and C:
- FileToDLOBH
- Inserts a new dlobh into the database from a file on disk.
It takes two arguments:
- Name: input file name.
- Type: large object type,
I for internal (large_object) and X for external
(external_file).
- DLOBHToFile
- Copies a dlobh from the database into a file on disk.
It takes two arguments:
- Dlobh: the dlobh to output.
- Name: output file name, which becomes the stub for
the filename.
For example, the following SQL statements create a table and insert the
C standard i/o header first as an internal large_object,
then as an external file.
$ msql test
* create table test_dlobh (foo dlobh);
* insert into test_dlobh values (FileToDLOBH('/usr/include/stdio.h','I'));
* insert into test_dlobh values (FileToDLOBH('/usr/include/stdio.h','X'));
Next, we copy both files back out onto disk and check for the files that
were created in /tmp.
* select DLOBHToFile(foo, '/tmp/dlobh') from test_dlobh;
* \g
$ ls -l /tmp/dlobh.*
-rw-r--r-- 1 miadmin 10 12420 Nov 21 11:25 /tmp/dlobh.2001
-rw-r--r-- 1 miadmin 10 12420 Nov 21 11:25 /tmp/dlobh.stdio.h
Selecting a dlobh returns the handle, which uses the internet
Uniform Resource Locator
(URL)
convention:
$ msql test -w 0
* select foo from test_dlobh;
-----------------------------------------------------------
|foo |
-----------------------------------------------------------
|dlobh://arcadia.CS.Berkeley.EDU/default/test/pbrown//I/I0105826192499|
|dlobh://arcadia.CS.Berkeley.EDU/default/test/pbrown//X:728911045:0//usr/include/stdio.h|
-----------------------------------------------------------
The URL fields for the dlobh are as follows:
dlobh://HOSTNAME:PORT/SERVER/DATABASE/USER/PASSWORD/TYPE/LOHANDLE
2. MDARRAY
Jean's note: I haven't had time to integrate all the information
for this section that Sunita has given me.
The default Illustra array type supports arrays of arrays.
The Big Sur mdarray type supports actual multi-dimensional arrays,
storing the array as an external file.
It is similar to the array type implemented in POSTGRES Version 4.2.
A description may be found in Sequoia technical report s2k-93-32, available
via anonymous ftp from
s2k-ftp.cs.berkeley.edu:/pub/sequoia/tech-reports.
The following creates an mdarray and inserts a three-dimensional
array of data:
create table int_marray3 (a marrayof(integer));
insert into int_marray3 values ('(1:2, 0:3, 2:7), int2.4.6');
The following updates individual elements in the array, then a
range:
update int_marray3 set a[1,1,2] = 112;
update int_marray3 set a[1,1,3] = 113;
update int_marray3 set a[1,2,2] = 122;
update int_marray3 set a[1,2,3] = 123;
update int_marray3 set a[2:2,1:2,2:3] = '(2,2,1), int2.2.1';
The following selects the entire array, then a specific element, and
finally a two-dimensional hyperslap:
select * from int_marray3;
select a[1,1,2] from int_marray3;
select a[1:1, 1:2, 2:3] from int_marray3;
3. SAIF Enumerations
A SAIF enumeration is a list of named values. For example, the
UnitMeaning enumeration identifies the real-world units stored in
another variable. Its domain of values is large and includes metres,
miles, degrees, radians, years, and seconds.
A subset of the SAIF enumerations are implemented in the Big Sur
schema for those portions of the schema that use SAIF.
Supporting functions include:
- SaifEnumHelp
- With no argument, outputs a list of SAIF enumerations that have
been implemented. With the name of an enumeration as the argument,
returns the domain of values for that enumeration.
For example, the following SQL statements list the available enumerations,
outputs the values for UnitMeaning, then creates a table with a
UnitMeaning type and inserts into it.
return SaifEnumHelp();
return SaifEnumHelp('UnitMeaning');
create table enum_test (sample UnitMeaning);
insert into enum_test values ('degrees');
As mentioned above in the
SAIF implementation notes,
Big Sur Version 1 has implemented enumerations as text strings.
UnitMeaning is a prime example of an enumeration domain we will need to
be flexible.
 Sequoia Glossary
Sequoia Glossary
 Big Sur Introduction
Big Sur Introduction
 Design Approach
Design Approach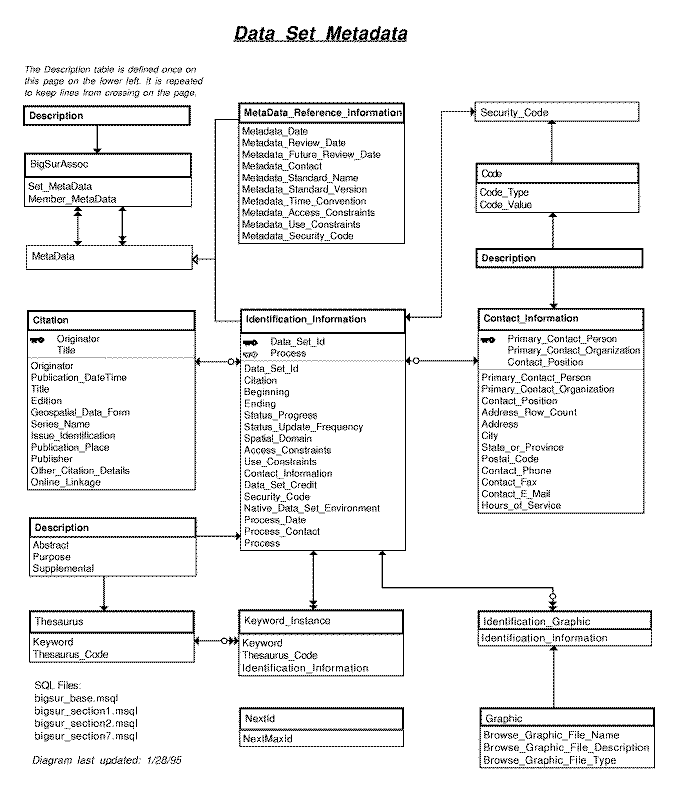{kind=link}
{kind=link}
{kind=link}
{kind=link}